

The IoT will give rise to the IoD – the Internet of (very Big) Data. The business opportunity is big too, but what about the costs?
How Big is Big Data?
Let’s start by discussing how big is Big Data. For example, Walmart customer transactions generate about 1 million data points per hour. Big, isn’t it?
Well, one single energy meter generates 1 million data points per day. This means that about 20 energy meters would generate as much data as 20,000 Walmart stores.
IoT and IoD: Big Data = Big Money?
If this sounds scary, it’s because you are thinking that big data equals big data storage – and consequently big money. And you’d be right, since this is what we have always been doing with data generated by human activities – store data first, use it later. But with the data volumes generated by things we need to rethink this approach.
Why do we need IoD Big Data?
Let’s start by reflecting upon the reasons why we might need big data generated by things. I believe that we can trim them down to 2 main categories:
- To discover something that we do not expect
- To respond to something that we do expect
We will discuss how can we achieve these goals effectively and without having to invest in huge data storage infrastructures.
Discovery
Let’s start with Discovery. This is mostly about finding unexpected patterns – and data aggregation makes it easier to visualise patterns. Data aggregation can be done in memory, propagating to data storage only aggregated data. This approach cuts the number of stored data records by 6 orders of magnitudes: taking the energy meter as an example, rather that storing 1 million data points per day this means storing just one single data record per day.
In Memory Data Stream Aggregation
The following diagram shows an example of pattern discovery enabled by in-memory data stream aggregation.
A printer’s usage and its energy consumption have been aggregated by hour along a 12 months period. We can see that energy consumption only increases marginally when the printer is in use, but it shows a steady profile in standby. We can also see that the printer gets into actual standby about 3 hours after its latest usage.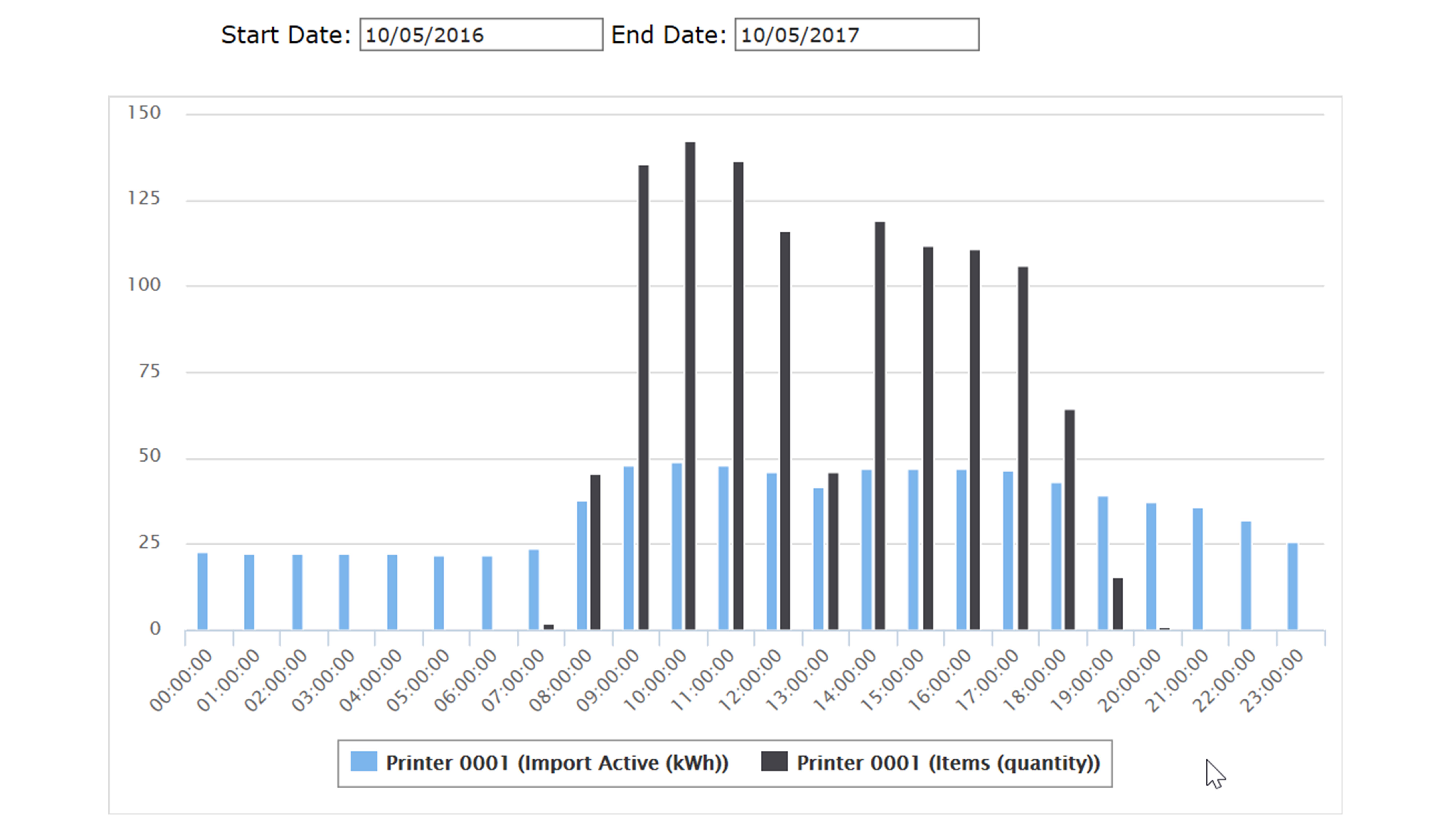
Responsiveness
Let’s now look at the second reason to use big data generated by things: responsiveness. As we said, this is about responding to something that we expect, which means matching live data to a known pattern. In this case storing individual data points for later analysis would not only be expensive – it would make it impossible to provide real time responsiveness. The best approach to real time pattern matching is in-stream data processing. More about Who owns the Machine Generated Data in IoT
In-Stream Data Analysis
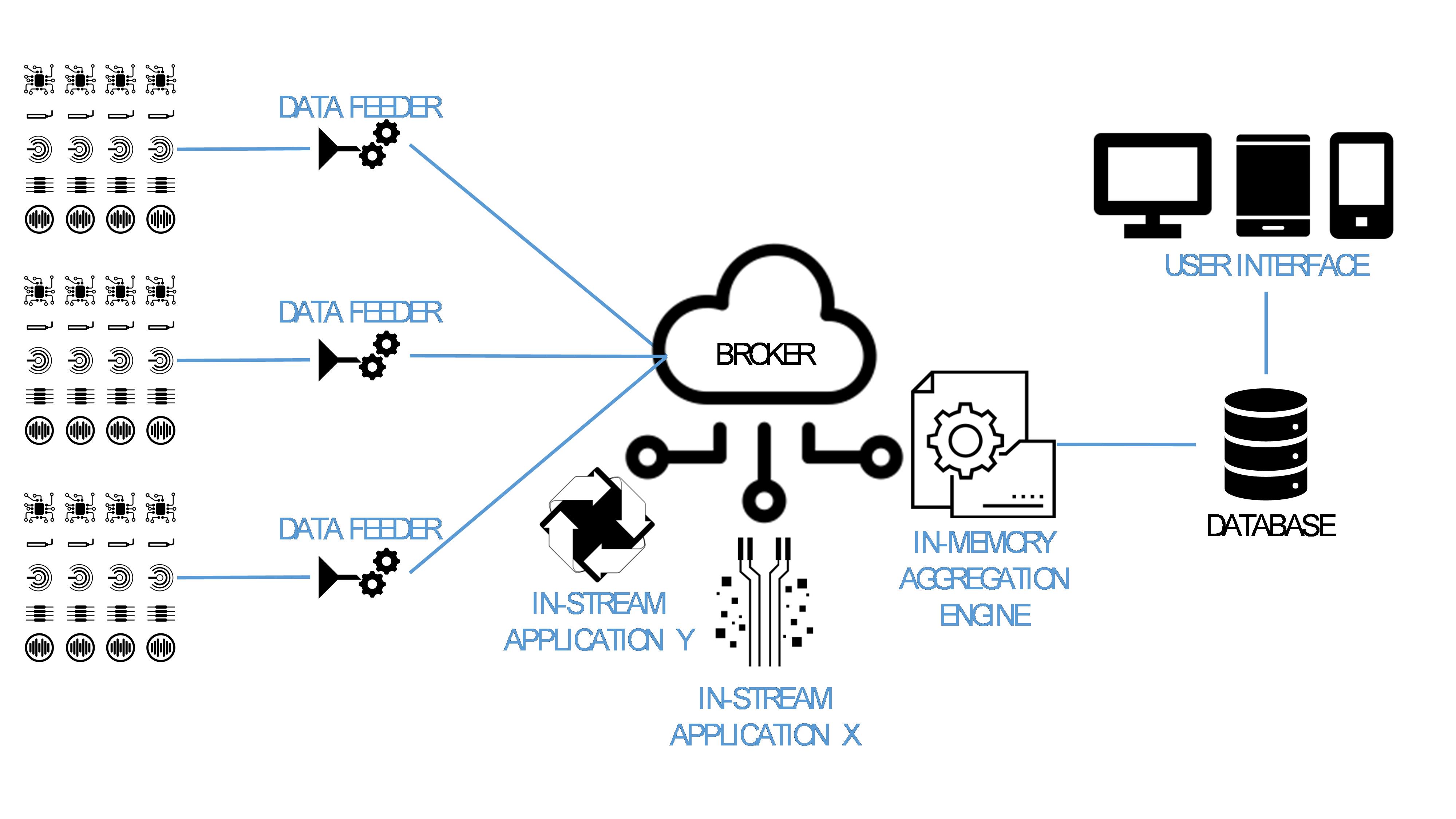
Sensor data streams can be processed in parallel by both aggregation and in-stream analysis applications.
In-stream data processing enables real time responsiveness in a variety of business scenarios, involving both individual assets and highly distributed organizations.
Real time responsiveness scenarios enabled by in-stream analytics include predictive maintenance, for both individual machinery and for complex sites, such as radio base stations, filling stations, office buildings etc. They also include the management of distributed infrastructures, such as electric car charging stations and multidirectional smart grids powered by distributed renewables plants.
Converting devices into data streams
In a previous article on IIoT World, I discussed the role of intelligent Feeders in converting industrial devices into real time data streams.
When used within broker centric architectures, Feeders can provide real time data streams to any kind and number of applications. One of these applications could be an in-memory data aggregation engine, to support pattern discovery. In parallel, the same data stream could be fed to a variety of in-stream data analysis applications to support real time responsiveness, e.g. for predictive maintenance and dynamic resources allocation. Find out more about the predictive power of big data analytics in the IIoT era.
IoT and IoD: Big Data at Small Cost
The IoT needs a new approach to managing data, that eliminates the equation big data = big storage by focusing on actual business needs – discovery and responsiveness.
Intelligent edge Feeders, broker-centric cloud architectures and in-memory data processing capabilities provide the technical foundation to meet these big needs – at a small cost.
Find out more about The Intelligent Edge: What it is, what it’s not, and why it’s useful
 This article was written by Elena Pasquali, the CEO of EcoSteer, an IIoT software company with offices in Italy and the US. EcoSteer key software product, the EcoFeeder, converts any kind & number of sensors and industrial devices into real-time data streams instantly accessible to multiple applications.
This article was written by Elena Pasquali, the CEO of EcoSteer, an IIoT software company with offices in Italy and the US. EcoSteer key software product, the EcoFeeder, converts any kind & number of sensors and industrial devices into real-time data streams instantly accessible to multiple applications.


