

Industrial AI is having its moment, and the pressure is real. Manufacturers are staring down a workforce gap that won’t resolve itself. As experienced people retire, the risk isn’t just “we need headcount.” It’s that tribal knowledge walks out the door, and what’s left behind is locked in PDFs, binders, scans, drawings, and vendor packages.
- up to 8M new workers needed by 2033; 1.9M roles at risk of going unfilled (Deloitte + The Manufacturing Institute)
- 65%+ cite attracting & retaining talent as the primary challenge (NAM outlook survey, Q1 2024, via Deloitte)
- 60% cite skilled labor shortages as the leading challenge to improving maintenance programs
- up to 400,000 U.S energy employees approaching retirement over the next decade (McKinsey)
- 92% implementing, developing, or planning new digital twin applications in the next five years (EY)
- 65% of respondents say their orgs are regularly using generative AI (McKinsey, early 2024)
So it’s no surprise teams are turning to copilots and automation. But the path from pilot to production is still messy. In industrial operations, AI doesn’t fail loudly. It fails quietly, with answers that sound right until they drive the wrong action.
That’s why the conversation turns fast from models and prompts to documents.
What operators keep telling me
Across manufacturing, energy, and asset-heavy infrastructure, I hear the same four patterns:
- “We tried RAG. The answers were plausible… and wrong.” (Explore what Document-first RAG means from Adlib).
- “OCR gets us text, but not meaning.” Tables, callouts, drawings, and footnotes cause silent failure.
- “We’re drowning in exceptions.” The edge cases become the main case.
- “Human review saves us, but it doesn’t scale.” Backlogs grow, and confidence drops.
Those aren’t inherently “AI problems.” They’re document reliability problems.
The missing layer: Document Accuracy & Trust
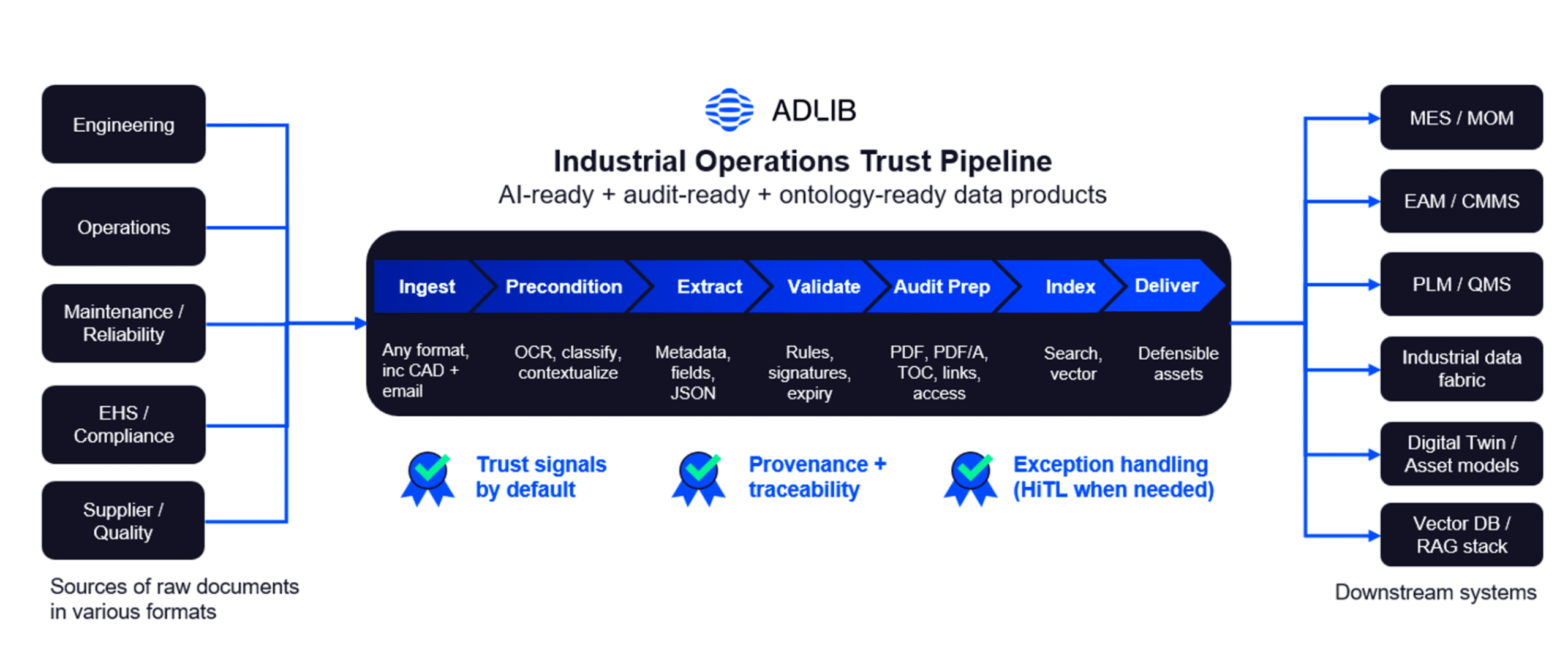
Before you build industrial AI workflows, you need a Document Accuracy Layer: a set of upstream controls that turns raw documents into AI-ready, audit-ready, ontology-compatible data products—with traceability and defensible outputs.
Think of it as a trust pipeline that forces one question at every stage:
“What can go wrong here, and how will we prove it didn’t?”
That “prove it” part matters more than ever, especially in safety-critical and regulated workflows.
A practical Document AI-readiness checklist
AI-ready means your document pipeline produces outputs that are repeatable, explainable, and defensible.
| Phase | Focus Area | Key Extraction Target |
|---|---|---|
| 1. Integrity | Pipeline Hygiene | Metadata spine, OCR quality, versioning |
| 2. Structure | Object Routing | Table extraction, layout awareness |
| 3. Meaning | Semantic Context | Targeted schemas, unit conversion |
| 4. Trust | Traceability | Chunk-to-source mapping, audit logs |
Quick self-test
If any of these are true, you’re not “AI-ready” yet, you’re “AI-adjacent”:
- You can’t confidently answer: “Which revision did this answer come from?”
- You can’t show field-level provenance (where the value came from in the source)
- Exceptions are handled with “just send it to a person”
- You can’t reproduce the same result twice (same inputs → same outputs)
1) Ingest: don’t start until you control inputs
Outcome: Every document becomes a known, trackable entity before extraction begins.
Look for:
- Coverage for the formats you actually have (including scanned PDFs, email attachments, image-heavy manuals, CAD exports)
- A minimum metadata spine: source, supplier/OEM, revision, effective date, asset/site context
- Clear identity rules: document IDs, versioning, and handling “duplicates that aren’t duplicates”
- Automated quarantine for corrupt/partial/locked files
Why it matters: Most “AI failures” start upstream, teams assume documents are clean and comparable, then discover they’re not.
2) Preprocess: object-aware preprocessing comes first
Outcome: Documents decomposed into building blocks so each element gets the right method and controls.
Look for:
- Document decomposition into object types (text blocks, tables, images, drawings, stamps, annotations)
- Object-level routing:
- OCR where text exists
- image optimization + vision models for graphics-heavy content
- table-aware extraction for embedded technical tables
- conversion where layout fidelity matters more than raw text
- Quality checks at the object level (skew, blur, resolution, compression)
- Layout/relationship awareness (headers ↔ tables, callouts ↔ drawings, footnotes ↔ values)
Why it matters: OCR produces characters when characters exist. Industrial decisions require meaning, and meaning depends on processing the right object the right way.
3) Extract: prioritize the fields that drive decisions
Outcome: Structured, decision-grade outputs, not an impressive text dump.
Look for:
- A defined target schema: fields, units, relationships, allowed values
- Outputs as fields + evidence, not just text chunks
- Table and multi-column competence
- A clear distinction between:
- detected (what the document says)
- interpreted (what the system infers)
High-value starters:
- equipment IDs, model/part numbers
- operating limits, safety thresholds (with units)
- maintenance intervals, torque specs, consumables
- inspection criteria and pass/fail logic
- revision/effective dates, applicability, superseded references
Why it matters: Adoption doesn’t happen because AI is fluent. It happens because it’s right where it counts.
4) Validate: trust signals by default
Outcome: Defensibility, the ability to explain why a value is trusted.
Look for:
- Rule-based checks (required fields, ranges, unit normalization, cross-field consistency)
- Revision validity checks (effective dates, approvals, superseded docs)
- Field-level provenance (page/section/coordinates or equivalent evidence pointers)
- Actionable confidence (not just a score, but a reason and next step)
- Exception categories (missing page vs ambiguous value vs conflicting revisions)
Why it matters: In industrial workflows, “pretty sure” is not a control.
5) Audit prep: preserve what you validated
Outcome: An audit-ready package where anyone can answer: What did we know, when did we know it, and what evidence supported it?
Look for:
- Preservation-safe source rendering (so it renders the same years later)
- Stored validation artifacts (rules triggered, normalizations applied, exceptions resolved)
- Locked evidence links (field-to-proof pointers that don’t break over time)
- Frozen revision context (revision/effective date + applicability by asset/site/config)
- Chain-of-custody logs (pipeline/version metadata: when, how, with what rules/models)
- Reproducibility (or explicit versioning when outputs change)
Why it matters: Validation proves something is right today. Audit prep ensures you can prove it later.
6) Index: retrieval must respect metadata and revisions
Outcome: Retrieval that stays accurate under operational constraints (asset/site/config/revision).
Look for:
- Indexing both extracted fields and narrative text
- Hybrid retrieval (keyword + vector) with strict metadata filters
- Chunk-to-source mappings so every answer can show evidence
- Guardrails against mixing revisions, sites, or applicability contexts
Why it matters: The most dangerous retrieval failure isn’t nonsense, it’s a confident answer grounded in the wrong revision.
7) Deliver + render: ship defensible assets, not just data
Outcome: Outputs downstream systems can consume without losing traceability, plus a document of record that holds up.
Look for:
- Delivery patterns that preserve lineage (not just CSVs)
- Auditable change logs (what changed, when, why, from which source)
- Controlled publishing (revision controls, approvals, chain-of-custody)
- A single pipeline that can produce both:
- structured, AI-ready data products and
- regulator-ready documents of record
Why it matters: In many industrial workflows, compliance ends when the final artifact is defensible, reproducible, and ready to stand on its own.
Closing thought
I don’t obsess over whether AI can generate an answer. I care whether operators can trust it at 2 a.m. when something is down.
That trust doesn’t come from prompts. It comes from defensible inputs: validated, revision-safe documents with traceable evidence.
If you’re building AI in industrial operations, start with one question:
Can you explain, field by field, why your AI should be trusted?
If not, don’t start with prompts. Start with your Document Accuracy Layer.
I will be speaking at IIoT World Energy Day on March 19, where this session will focus on how upstream compliance and document trust directly impact AI readiness in energy operations. The discussion will focus on practical architectures, governance controls, and measurable outcomes drawn from real operational environments. Registration is open, and attendees can sign up to join the session here.
About the Author
 Anthony Vigliotti builds Intelligent Document Processing systems and has a soft spot for the PDFs everyone else tries to ignore. He’s an engineer by training and a product developer by habit, who’s spent years in the trenches with customers chasing one goal: fewer exceptions, less human-in-the-loop, and more trust in document-driven automation.
Anthony Vigliotti builds Intelligent Document Processing systems and has a soft spot for the PDFs everyone else tries to ignore. He’s an engineer by training and a product developer by habit, who’s spent years in the trenches with customers chasing one goal: fewer exceptions, less human-in-the-loop, and more trust in document-driven automation.


